De PDF-paradox: onmisbaar in vastgoed, onbruikbaar voor echte digitalisering


Een bestandsformaat uit 1993 dat weigert te sterven
Toen Adobe in 1993 het Portable Document Format lanceerde, noemde een consultant van Gartner het "het domste idee dat ik ooit heb gehoord". Gebruikers moesten minutenlang wachten tot megabyte-grote bestanden over hun inbelverbinding gedownload waren. Het format leek gedoemd te mislukken.
Meer dan drie decennia later circuleren er wereldwijd meer dan 2,5 biljoen PDFs. In vastgoed is het bestandsformaat alomtegenwoordig.
Verkoopcompromissen, notariële akten, stedenbouwkundige attesten, bodembeschrijvingen, EPC-certificaten, kadastrale plannen — vrijwel elk juridisch document in een vastgoedtransactie bestaat als PDF. The Economist schreef er deze week nog over: het format is niet alleen springlevend, het is essentiëler dan ooit.
Waarom vastgoed zo afhankelijk is van PDFs
De kracht van de PDF ligt in zijn eenvoud: what you see is what you get. Een notariële akte in PDF ziet er identiek uit op de laptop van de koper, de tablet van de makelaar en de desktop van de notaris. Dat is precies wat je wilt bij juridisch bindende documenten — visuele integriteit, ongeacht het apparaat.
Voor vastgoedprofessionals biedt de PDF daarnaast een laagdrempelige manier om documenten te archiveren en te delen. Geen speciale software nodig, geen compatibiliteitsproblemen, geen verlies van opmaak. Het is de digitale equivalent van een papieren dossier.
Het fundamentele probleem
Een PDF is geen data
Maar hier schuilt het paradox. Een PDF is in wezen een visuele representatie van informatie — een digitale foto van een document. De tekst die je ziet is niet gestructureerd. Een kadastraal inkomen dat in een PDF staat, is voor een computer niet anders dan een willekeurig getal op een willekeurige positie op een pagina.
Een PDF is een visuele container. Geen dataset.
Dit heeft verregaande gevolgen voor wie vastgoed écht wil digitaliseren:
Geen gestructureerde extractie
Wanneer een vastgoedprofessional een verkoopcompromis ontvangt als PDF, moet iemand — mens of AI — de relevante gegevens er handmatig uit halen. Oppervlakte, kadastraal inkomen, stedenbouwkundige bestemming, erfdienstbaarheden: het staat er allemaal in, maar het is opgesloten in een ongestructureerd format.
AI hallucineert op PDFs
Zoals The Economist deze week rapporteerde, worstelen grote taalmodellen met PDFs. Ze lezen kolommen van links naar rechts in plaats van van boven naar beneden, raken in de war door headers en footers, en genereren soms complete onzin. Dit is bijzonder relevant voor vastgoed, waar de nauwkeurigheid van geëxtraheerde data juridische implicaties heeft.
Geen machine-readable metadata
Een EPC-certificaat in PDF bevat het energielabel, maar een systeem kan dat label niet automatisch uitlezen en vergelijken met andere woningen. Elk document moet individueel verwerkt worden — een tijdrovend en foutgevoelig proces.
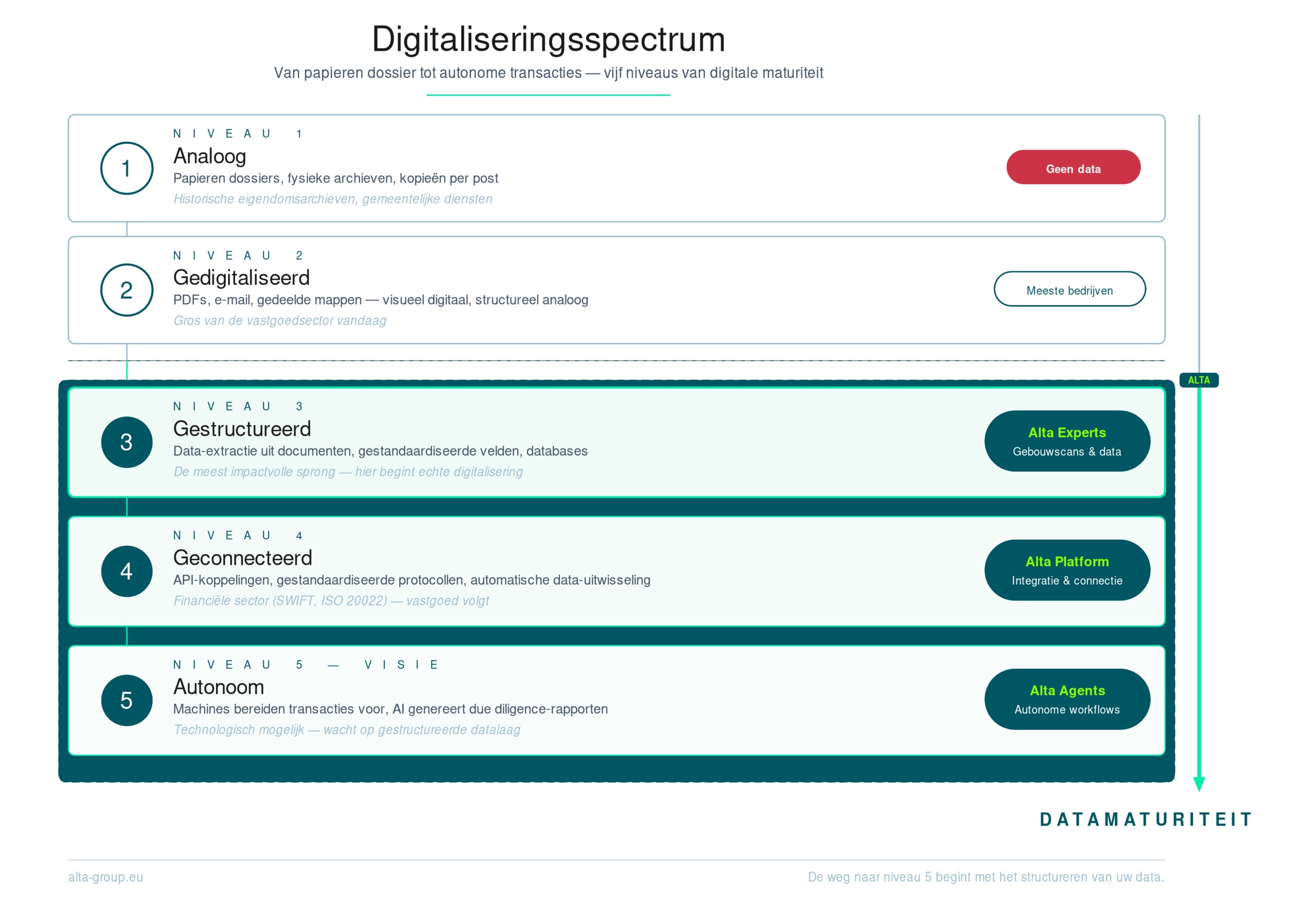
De vastgoedsector zit vast in de jaren 1990
Het resultaat is een sector die weliswaar "digitaal" werkt — documenten worden per e-mail verstuurd in plaats van per post — maar die qua datamaturiteit nog in de jaren negentig zit. Er worden miljarden euro's aan vastgoedtransacties afgehandeld op basis van informatie die opgesloten zit in niet-doorzoekbare, niet-koppelbare, niet-analyseerbare PDFs.
Vergelijk het met de financiële sector, waar gestructureerde data-uitwisseling al decennia de norm is. Of met de automobielsector, waar een CarPass gestructureerde historische data bundelt. In vastgoed ontbreekt die infrastructuur grotendeels.
Van PDF naar gestructureerde data
De weg vooruit
De oplossing is niet om PDFs af te schaffen — daarvoor zijn ze te diep verweven met juridische processen en regulering. De oplossing is om een datalaag te bouwen bóvenop de bestaande documentenstroom.
Dat betekent concreet: technologie die PDFs kan parsen met hoge nauwkeurigheid, de geëxtraheerde data structureert in gestandaardiseerde formats, en die gestructureerde data beschikbaar maakt voor analyse, vergelijking en besluitvorming.
Bij Alta Group is dit precies wat we bouwen. Onze technologie extraheert gestructureerde data uit de documenten die vastgoedtransacties aansturen — en maakt die data beschikbaar in een format dat wél doorzoekbaar, koppelbaar en analyseerbaar is.
Conclusie
De PDF is niet het probleem. Het is een briljant bestandsformaat dat doet waarvoor het ontworpen is. Het probleem is dat we zijn gaan denken dat een PDF "digitale data" is. Dat is het niet. Het is een visuele container.
Echte digitalisering in vastgoed begint waar de PDF eindigt: bij gestructureerde, machine-readable, koppelbare data. Wie dat onderscheid begrijpt, begrijpt waarom de vastgoedsector — ondanks alle technologische vooruitgang — nog steeds wacht op zijn echte digitale transformatie.